Procedure 5: Loading Data into h2O with R
Start by loading the FraudRisk.csv file into R using readr:
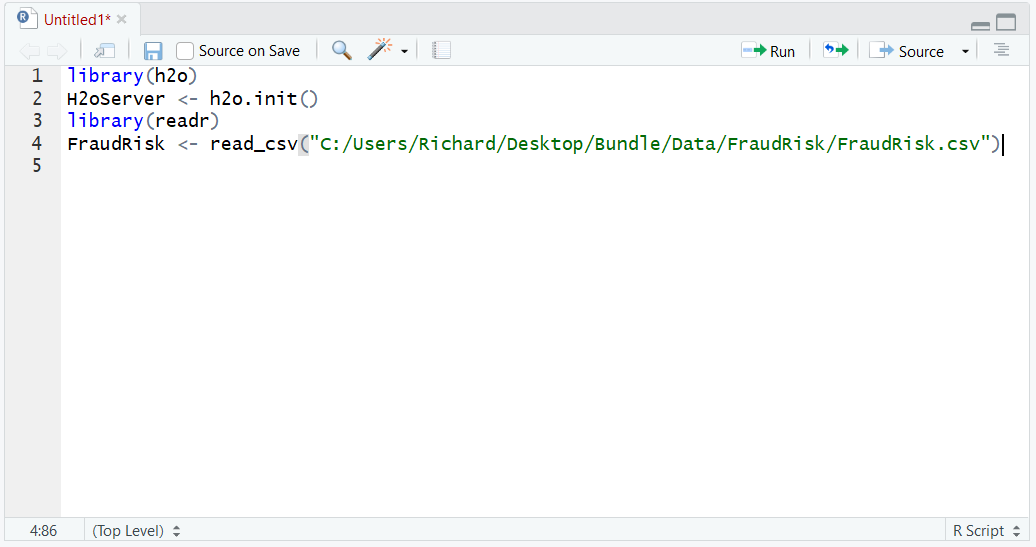
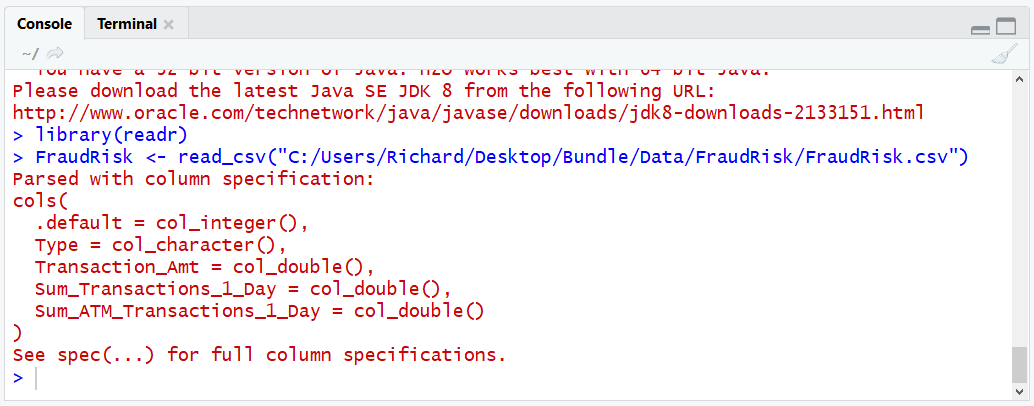
library(readr)
FraudRisk <- read_csv("C:/Users/Richard/Desktop/Bundle/Data/FraudRisk/FraudRisk.csv")
Run the block of script to console:
The training process will make use of a test dataset and a sample dataset. The preferred method to randomly split a dataframe is to create a vector which comprises random values, then append this vector to the dataframe. Using Vector sub setting, data frames will be split based on a random value.
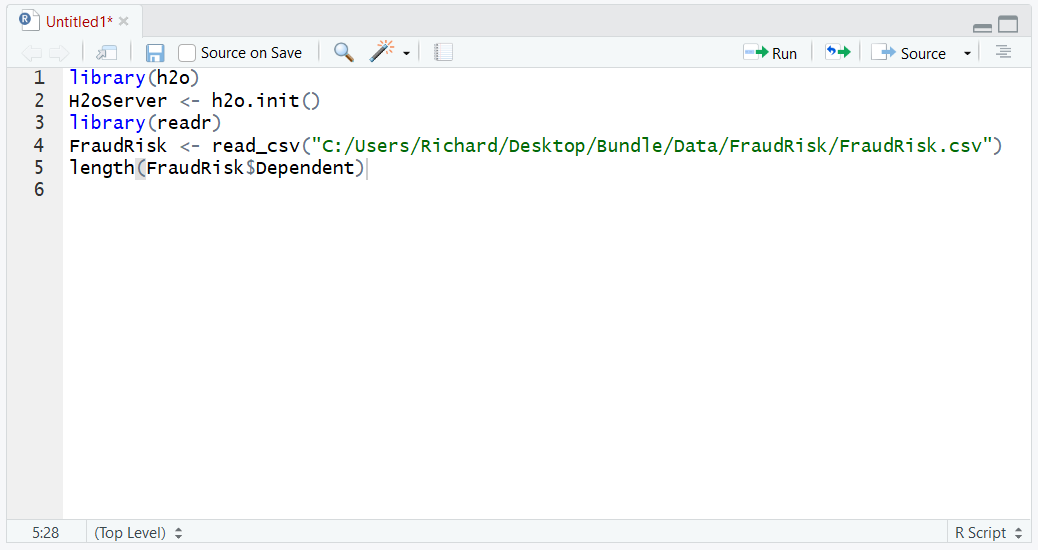
Start by observing the length of the dataframe by typing (on any dataframe variable):
length(FraudRisk$Dependent)
Run the line of script to console:
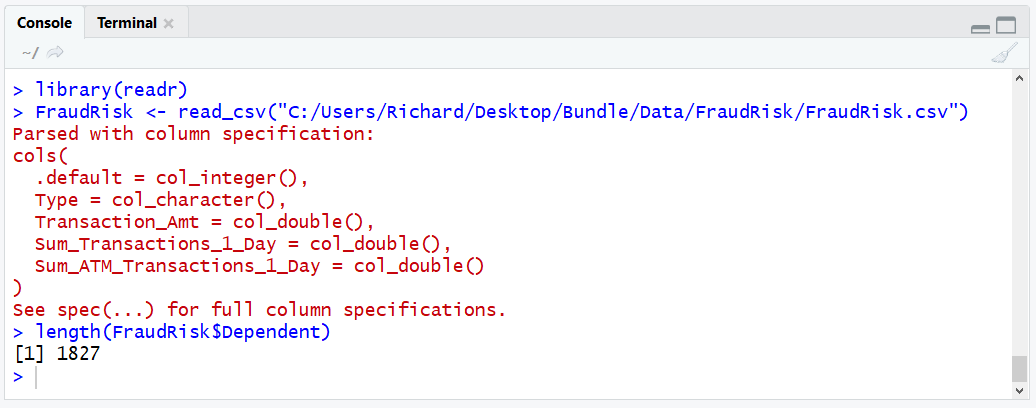
Having established that the dataframe has 1827 records, use this value to create a vector of the same size containing random values between 0 and 1. The RunIf function is used to create vectors or a prescribed length with random values between a certain range:
RandomDigit <- runif(1827,0,1)
Run the line of script to console:
A vector containing random digits, of same length as the dataframe, has been created. Validate vector by typing:
Run the line of script to console:
The random digits are written out showing there to be values created, on a random basis, between 0 and 1 with a high degree of precision. Append this vector to the dataframe as using Dplyr and Mutate:
library(dplyr)
FraudRisk <- mutate(FraudRisk,RandomDigit)
Run the block of script to console:
The RandomDigit vector is now appended to the FraudRisk dataframe and can be used in sub setting and splitting. Create the cross-validation dataset by creating a filter creating a new data frame by assignment:
CV <- filter(FraudRisk,RandomDigit < 0.2)
Run the line of script to console:
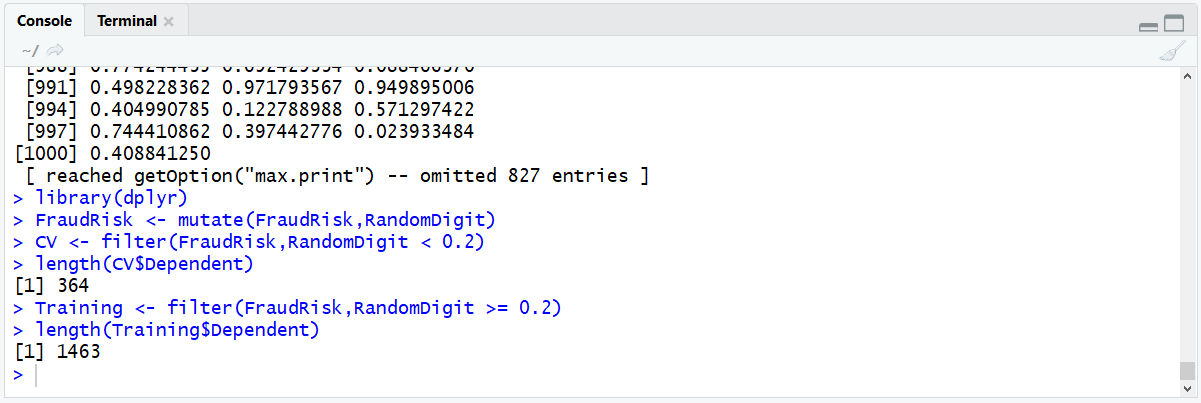
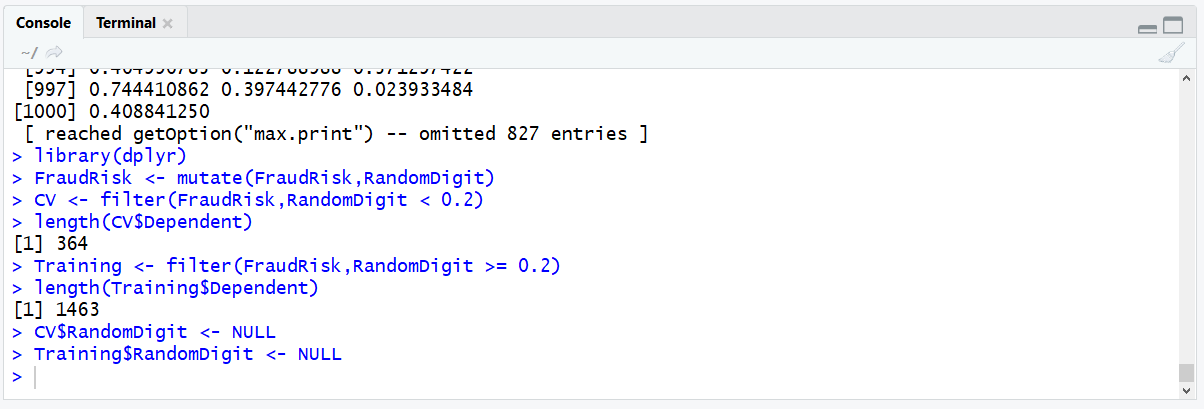
A new data frame by the name of CV has been created. Observe the CV data frame length:
length(CV$Dependent)
Run the line of script to console:
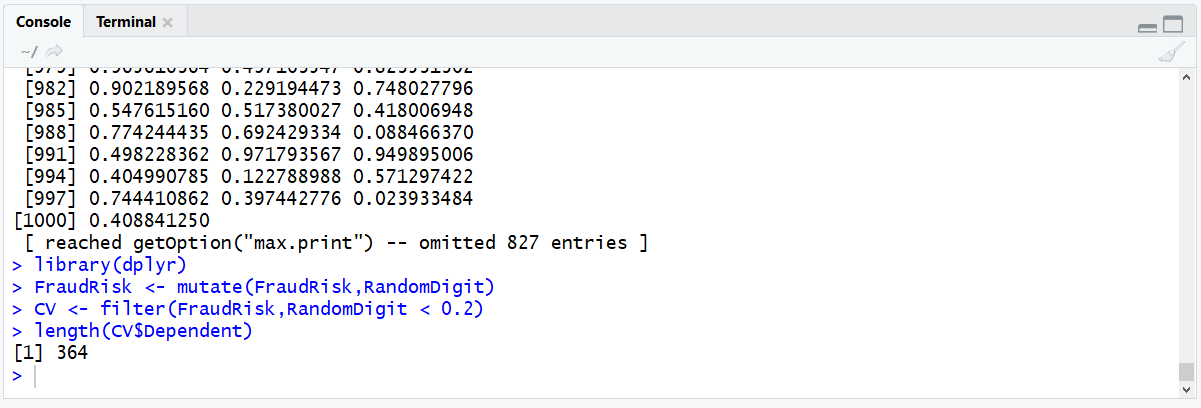
It can be seen that the data frame has 386 records, which is broadly 20% of the FraudRisk data frames records. The task remains to create the training dataset, which is similar albeit sub setting for a larger opposing random digit filter:
Training <- filter(FraudRisk,RandomDigit >= 0.2)
Run the line of script to console:
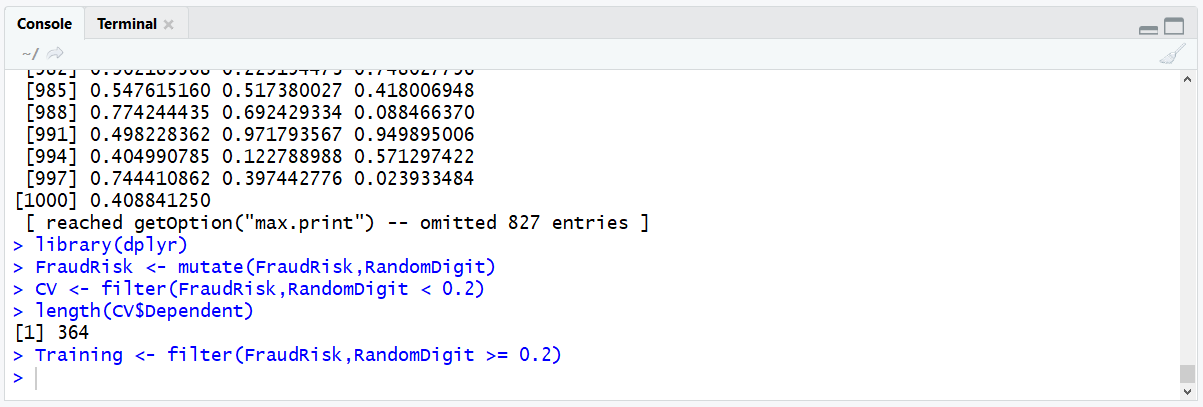
Validate the length of the Training data frame:
length(Training$Dependent)
Run the line of script to console:
It can be observed that the Training dataset is 1463 records in length, which is broadly 70% of the file. So not to accidentally use the RandomDigit vector in training, drop it from the Training and CV data frames:
CV$RandomDigit <- NULL
Training$RandomDigit <- NULL
Run the block of script to console:
H2O requires that the Dependent Variable is a factor, it is after all a classification problem. Convert the dependent variable to a factor for the training and cross validation dataset:
Run the line of script to console:
At this stage, there now exists a randomly selected Training dataset as well as a randomly selection Cross Validation training set. Keep in mind that H2O requires that the dataframe is converted to the native hex format, achieved through the creation of a parsed data object for each dataset. Think of this process as being the loading of data into the H2O server, more so than a conversion to Hex:
Training.hex <- as.h2o(Training)
CV.hex <- as.h2o(CV)
Run the block of script to console:
All models that are available to be trained via the Flow interface are available via the R interface, with the hex files being ready to be passed as parameters.